Direct Query vs Ingested Data
Pass-through datasources can be natively queried by Pyramid with direct queries. This means that the data does not need to be pre-processed or copied by Pyramid (or any other technology) before it can be queried by users. Instead, the user allows Pyramid to directly query selected tables in the given database. Direct querying is useful if you wish to query a single data source (as opposed to combining tables from multiple sources) and have no need to perform any manipulations or data cleansing on the dataset.
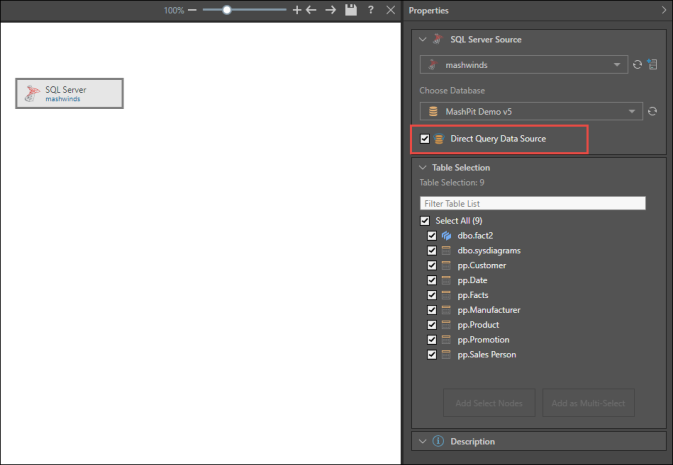
Direct Querying
Direct querying is powerful because it requires minimal setup and ensures that queries are built with the real-time data. As there is no data model output, there is no need to create any scheduling. Instead, whenever a user builds a query, Pyramid queries the actual data source, rather than data that was copied into Pyramid.
When setting up direct querying for a data source, additional nodes cannot be connected to a direct query datasource node. Once you've selected this option you can continue directly to the Data Model part of the ETL, where you can construct the semantic data model.
Direct querying setups don't require database and model reprocessing in order to keep data updated. However, changes made to metadata in the semantic data model do require you to reprocess the model.
- Click here for a list of datasources that can be queried directly.
Note: MS Analysis Services (OLAP and Tabular) can be directly queried using their existing cubes and tabular models.
Pyramid Models
Sometimes, data is stored in such a way that does not require any cleansing prior to querying; in such cases, direct querying can be a good solution. However, often data is stored across a range of sources and formats. These setups may require a number of manipulations to ensure that the resulting data model can be easily analyzed and understood. Data ingestion allows the model-builder to apply a range of data cleansing and preparation processes during the ETL; something that is not supported by direct querying.
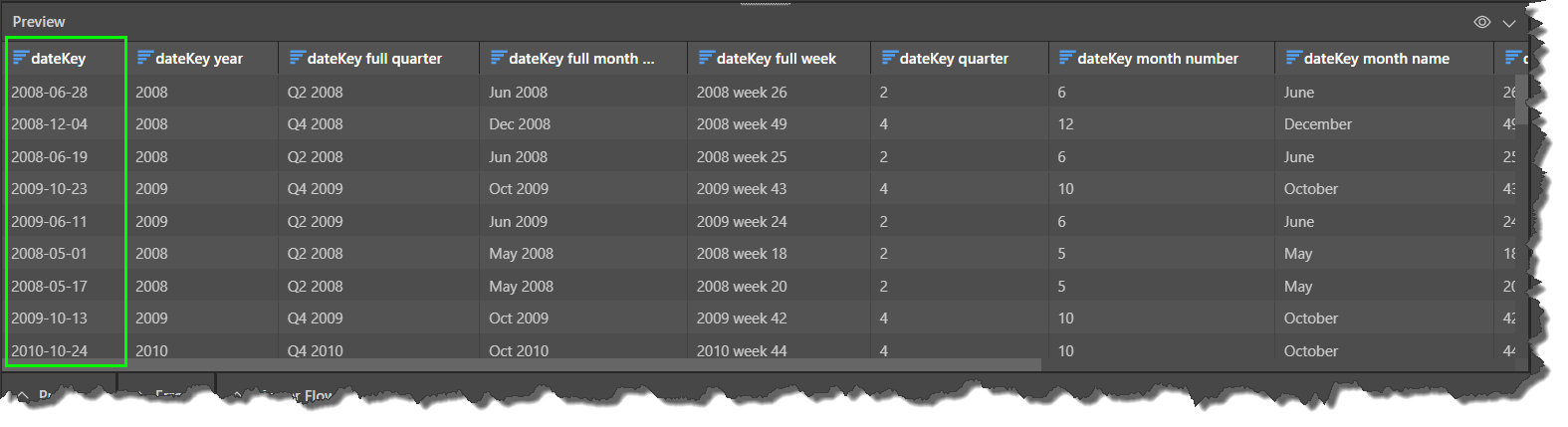
A common example is to add Time Intelligence to a dateKey column in order to extract a number of logical date-time columns (like year, month, quarter, and week), that facilitate date-time analysis. In the example below, multiple date groupings were extracted from the dateKey column (green highlight) in the datasource. It would be extremely difficult for report-builders to perform date-time analysis with just the original dateKey column. But with the new columns generated by the Time Intelligence node, they can easily analyze and compare dates and time periods.
Data ingestion also allows you to create data mashups, creating a new model based on datasets from multiple sources. Say you have sales data stored in SalesForce, product and marketing data stored in an SQL database, and staff and team data stored in a local file. You can connect to the relevant sources and copy the required tables from each source, and then create the necessary joins between the tables.
Batch Processing
Ingesting data to produce a Pyramid model requires the user to consider the frequency of scheduled re-processing, in order to keep the model updated. This is an extremely important piece of model management and the data pipeline; if the model is not re-processed according to an appropriate schedule, data analysis and querying will not accurately reflect the data source. The resulting reports may be inaccurate and misleading.
Pyramid uses batch processing to collect data and reprocess the model according to user-defined conditions or schedule.